The noindex tag is a meta tag or directive used in a web page's HTML code or HTTP header response to instruct search engines not to index the page. When you noindex a page, it will not appear in search engine results for relevant SEARCH queries on Google, Bing, and other search engines.
The noindex tag is part of the robots meta tags family, which provides web crawlers and robots instructions about handling a page's content.
There are a few different ways to implement the noindex directive on a web page:
<meta name="robots" content="noindex">
This meta tag goes inside the <head> section of the page's HTML code. The "noindex" value in the content attribute tells search engines not to index and list that specific page in their organic search results.

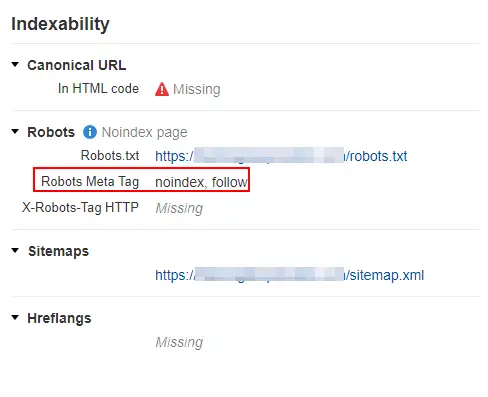
X-Robots-Tag: noindex
When a browser requests the page, search engines can return this noindex directive in the HTTP response headers. The X-Robots-Tag HTTP header overrides any conflicting robots meta tag in the HTML.
There are several legitimate use cases for noindexing pages:
| 1 | Login Pages | It's standard to noindex login, account, and other private user pages to prevent search engines from publicly indexing and showing this sensitive content. |
| 2 | Low Quality/Duplicate Content | Websites may noindex pages with thin/duplicate content, pagination pages, guest posts, and other low-value pages that don't deserve prominent search rankings. |
| 3 | Secondary Content | Sections like shopping carts, filtered navigation pages, and other secondary content meant just for visitors may need noindexing to conserve the crawl budget. |
| 4 | Staging/Development Environments | Noindex tags prevent search engines from indexing non-production site versions during development. |
| 5 | Avoiding Duplicate Content Issues | Using a noindex meta tag or HTTP header on all but one canonical version can help avoid duplicate content penalties if you have pages with duplicate content that are similar. |
Noindex vs. Nofollow
While noindex prevents indexing of a page's content in search, the nofollow tag instructs engines not to pass link equity from that page to its outgoing link destinations. Using noindex, nofollow together is common for pages you don't want indexed or influencing rankings.
Robots.txt
The robots.txt file provides crawler instructions at the domain level. Using noindex tags or headers is also a way to manage indexing at the individual page level.
Canonical Tags
If you have duplicate page versions, using a self-referencing canonical tag plus noindexing all non-canonical versions can firmly establish the canonical URL.
Google provides several tools to give you transparency and control over what is or isn't included in their index for your website. These include:
Google Search Console
In this tool, you can inspect your site's index coverage, submit pages for re-crawling, and remove outdated content using the URL removal tool.
URL Inspection Tool
Check if Google has successfully indexed, or appropriately noindexed, a specific page on your site.
Advanced Settings
There are also advanced noindexing capabilities in Google Search Console under Settings > Indexing & Ranking to noindex your entire site or apply wildcard noindexing patterns.
While noindexing pages judiciously can be wise, you also want to ensure your most important content is fully optimized for search engines.
At SEOLeverage, our experts can audit your site's indexability and optimize your highest-value pages for maximum visibility in Google and other search engines. Leverage our SEO services to drive more qualified organic traffic. Request a free consultation today.